再议降本增效
当前这个大背景下,无论大中小厂都在提降本增效,毫无疑问,裁员的效果最是立竿见影,简单又粗暴,可见当下人力成本之高,人员之冗余,以至于,似乎,更卷了。作为一个不油腻,长期居于一线的软件工程师,无法影响大趋势,只能从软件工程的角度,试图践行“降本增效”。
降本增效的经验套路,即使过去5年,在当下依然适用。鉴于贵司特殊的业务场景,笔者主要通过开发测试环境中间件的资源共享来阐述降本增效的理念。
Kafka
贵司至少在开发(dev)、测试(test)环境各部署了一套Kafka,然后dev、test环境网络还是互通的,Kafka还是三实例部署在一台主机上,形如:
version: '3'
services:
kafka1:
……
kafka2:
……
kafka3:
……
我也是不太明白这样的“高可用”部署到底有何意义?所以kafka降本的方法也就呼之欲出了
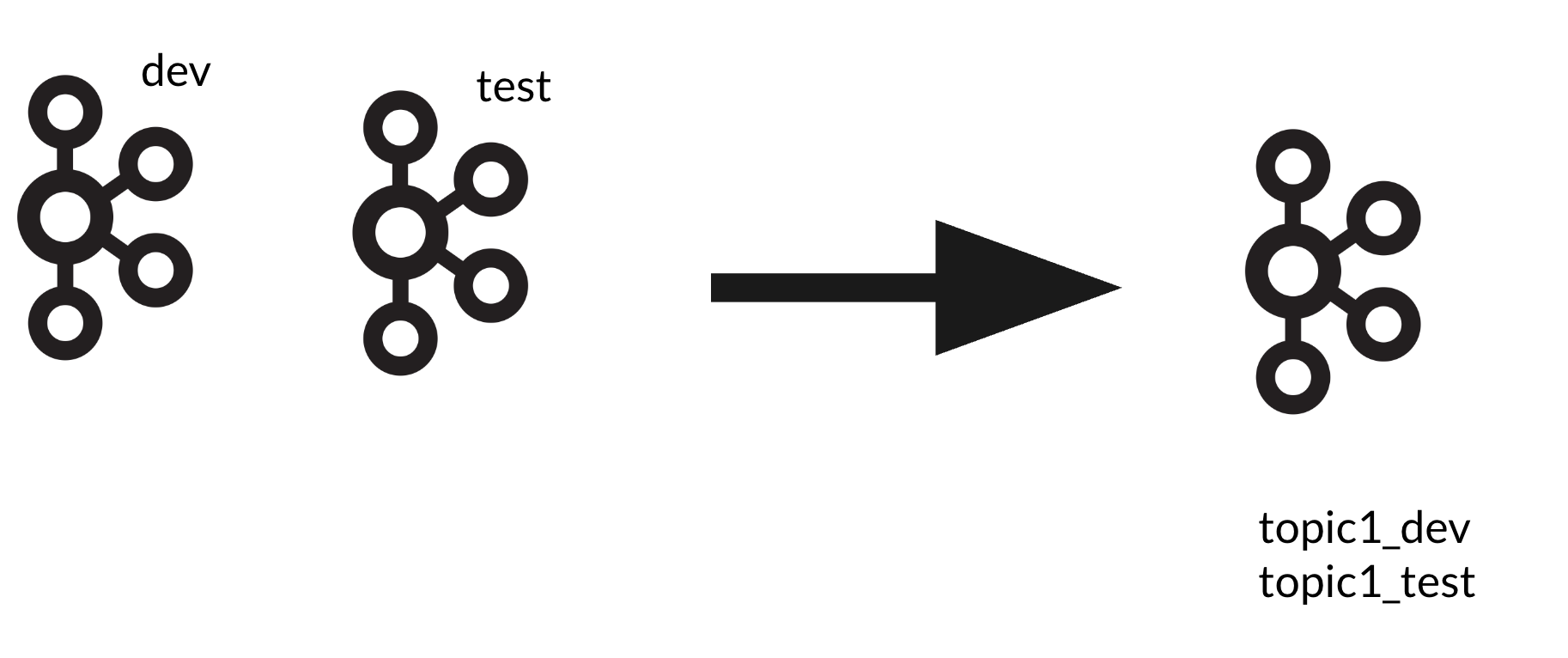
是的,没错,dev、test环境“高可用”的kafka合为一个共享的单实例 kafka。dev、test环境那小的可怜的数据量,搞什么高可用嘛,纯属浪费资源了。topic以环境变量为后缀作区分,改动起来,成本真的非常低了。嗯,就是这么简单,不用任何华丽的招式,效果却是毋庸置疑的。
Redis
这个我不太愿意说,因为同事把redis当分布式锁用,而调用redis的服务却是单实例部署的……当然,redis也是dev、test各单实例部署一个,照猫画虎喽
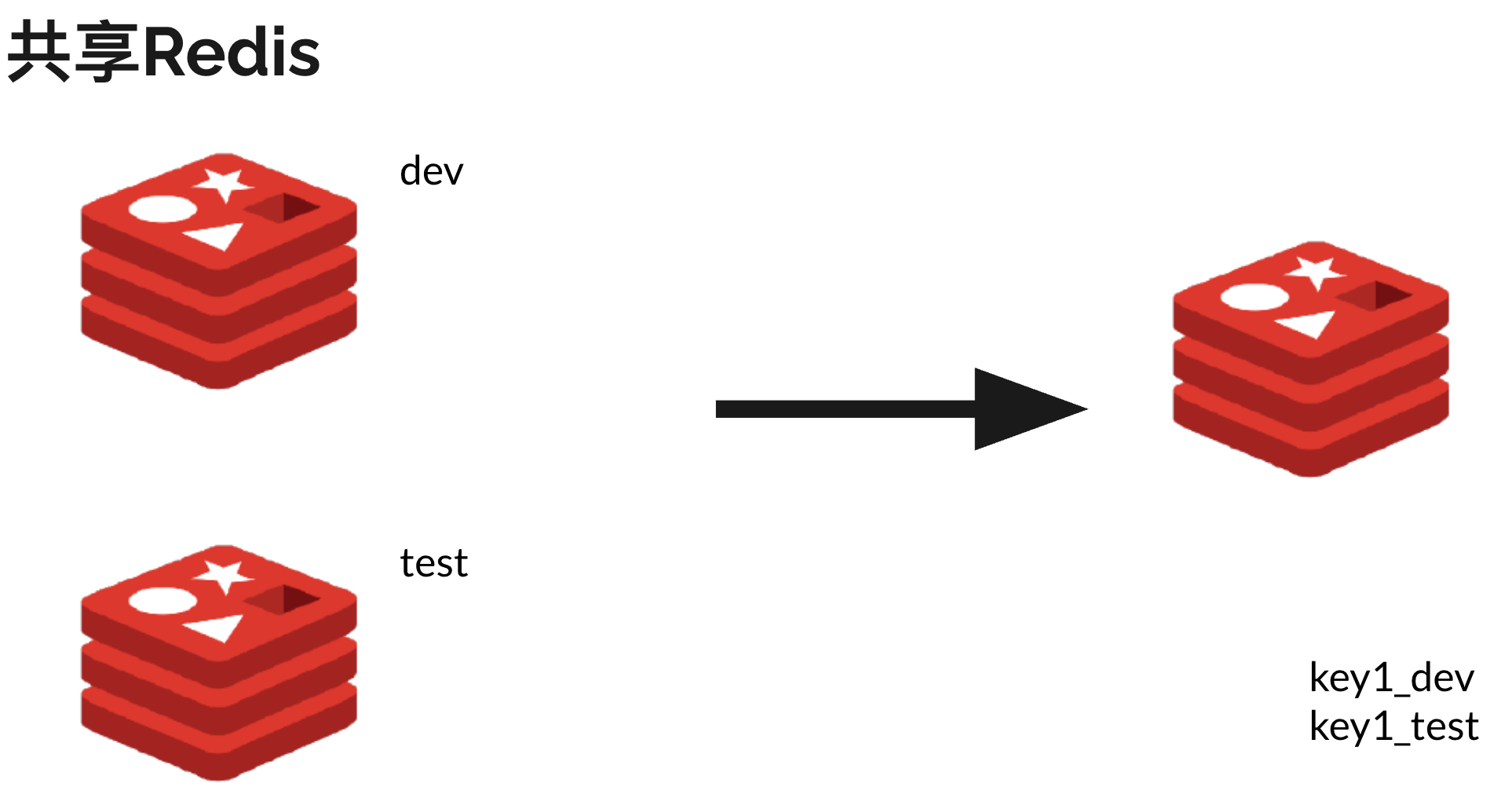
方法是一样的,但这这个效果就没kafka明显了。
MySQL
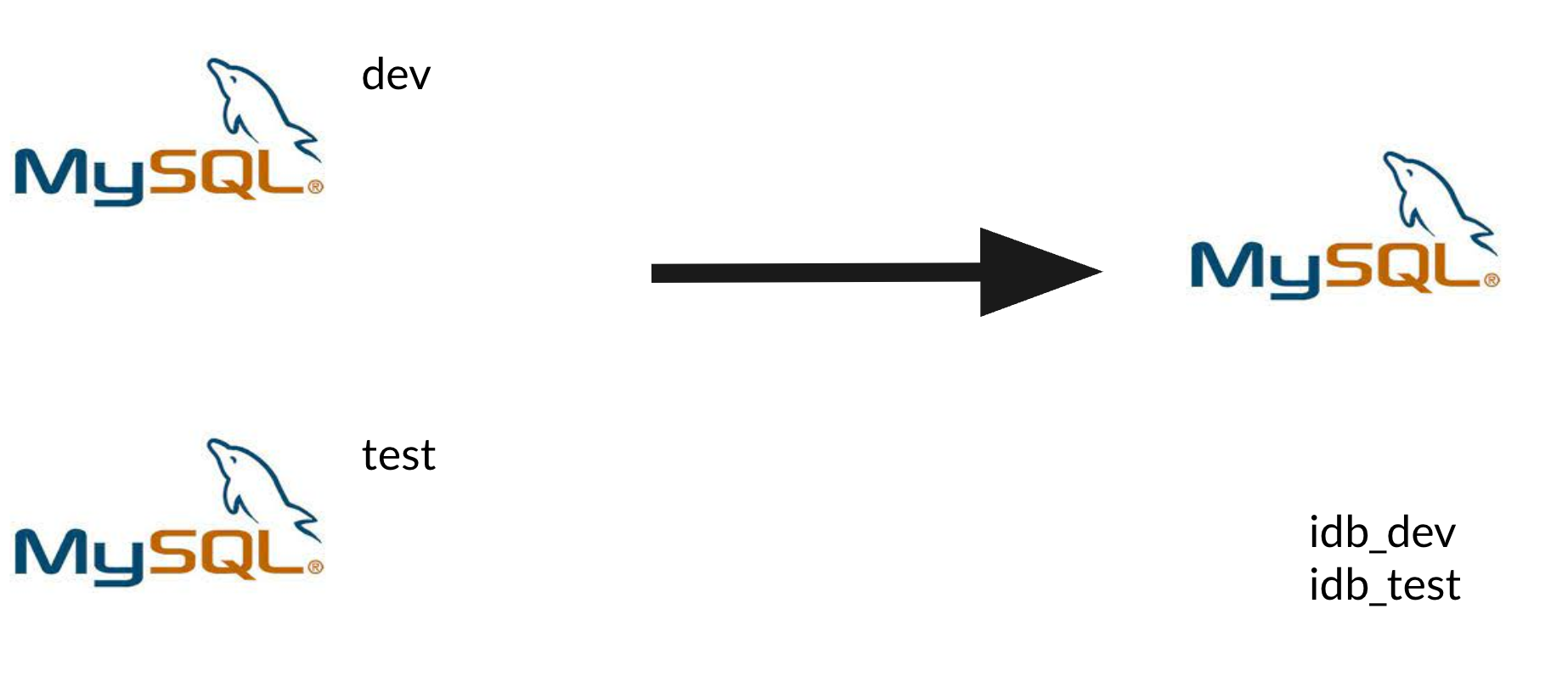
因为团队业务数据大多是配置型的,单表数据超过1k都很难,数据量实在是少的可怜(我甚至都在想要不直接用SQLite算了)。
不得不说,mysql数据共享是最容易想到,而且没有任何改造成本,但依然dev、test环境各单实例部署了一个,共享的方法当然也就非常简单了
其它
至于共享Grafana与Elasticsearch,方法都是一样的,可能有人担心隔离性、误删数据等问题,这个担心有一定的道理,但是各环境分别部署,就能避免这个问题?显然不能吧,当然dev、test环境的权限管控还是要做的,这个话题就不在这里展开了。
总结
这几年工作中总是碰到一些奇怪的情况,比如XX大厂在用这个开发框架,我们也用;明明不到1k的实际使用用户,却大谈高并发……大厂崇拜的现象还是很严重的,当然,我也曾经历过那样的时光。具体问题还是要具体分析,技术领域也从来没有银弹,百花齐放才是常态。因地制宜,不生搬硬套,能根据实际的业务场景,使用合适的技术,这才是一个软件工程师应该做的。合适就是平衡之术:时间成本、开发成本、维护成本……。不得不再次放出我很喜欢的一句话了:
工程思维:永远以资源有限、条件不足为前提,去实现现实世界的目标。