mPaaS 平台降本增效实践
注:本文本是笔者在公司内部的投稿文章,已通过还没来得及发布就领了大礼包……
自打进入2022年,行业内不少公司都在提降本增效,我司也不例外,不过对于降本增效的理解,自然是仁者见仁,智者见智了。笔者对降本增效的理解分为两块:
- 降本
- 增效
1. 降本
降本,故名思义: 降低成本,降低成本一定是因为做同样一件事情,成本过高或者是存在浪费的情况。其实在公司层面开始执行降本增效之前,笔者就已开始在 mpaas 平台推动这件事了。现在想来,是因为笔者偶然在公司的监控中心注意到 mpaas 的后端服务的负载普遍偏低,这引起了笔者的兴趣,于是才有了接下来了一系列操作,且听我娓娓道来。
1.1 容器化部署
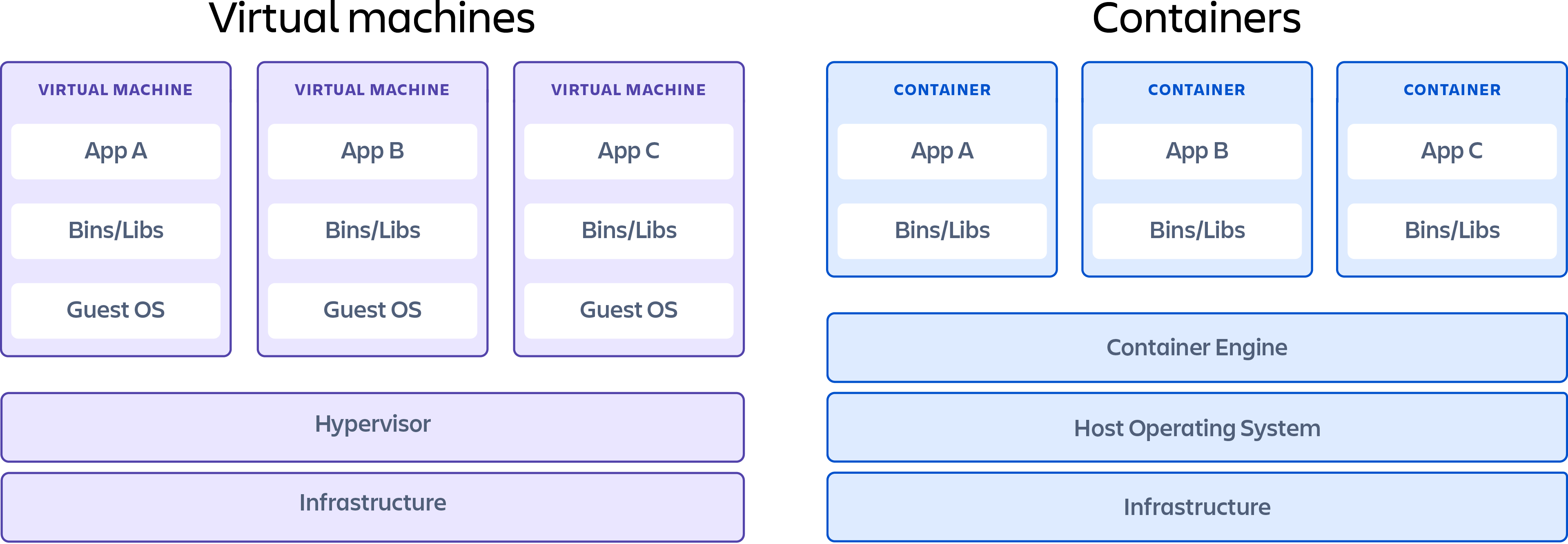
早期 mpaas 后端服务从开发到发布往往要经过以下几步:
- 本地完成需求开发与测试;
- 将工程编译打包成 docker 镜像;
- 上传至公司私有的 docker 镜像中心;
- 登录虚拟机下载 docker 镜像并启动;
可以看到,因为步骤较多,而且因为没有相应的操作规范,整体的效率是比较低的。彼时公司有PL发布系统(现已关闭,迁移到了DevOps平台,为方便起见,后文统一指代为发布平台),可以支持将应用部署到 k8s 平台。因为笔者有过相关经验,于是便和同事一起将 mpaas 后端应用迁移到公司的发布平台进行发布。现在来看,mpaas 平台容器化最重要目的一点还是借力公司的发布平台,将过往非标准化的虚拟机部署服务的模式,标准化部署到公司的 k8s 平台,下图是 k8s 的架构图:
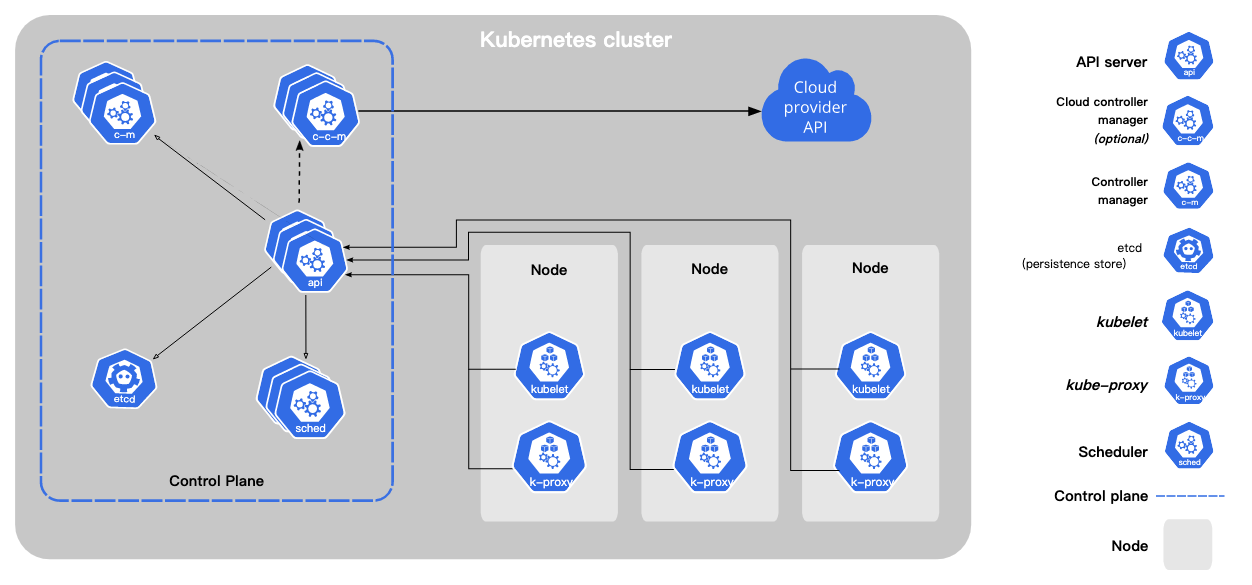
可以看到,k8s 本身还是相当复杂的,而因为借力公司的发布平台后,部署一个微服务将会变得非常容易,而且很自然地接入了公司的运维监控体系;从公司层面上来讲,相较于在虚拟机部署,k8s 平台的资源利用率也得到了提高。综合来看,这是一件一举多得的事情。
前面提到 mpaas 大部分微服务都已经迁移到 k8s 集群部署,但是因为公司的后端技术栈主要是以 java 为主,众所周知,java 服务是比较吃资源的,运维的许多配置支持明显是倾向于 java 的,单就服务资源规格来看,1核1G是最低配置了,但是对于 mpaas 的后端服务而言,我们只需要0.5核0.5G足已,没办法,就是这么优秀。经过跟运维团队的强烈建议,0.5核0.5G终于成为发布平台资源配置的一个可选项,至此,光是降低配置这一项,mpaas 后端就省了不少。
1.2 微服务化
这几年容器化、微服务的概念大行其道,不少人将其奉为圭臬,笔者也曾如此。在开发人员充足、业务繁杂的情况下,微服务确实在一定程度上提高了开发速度,但是正如每个硬币都有两面一样,微服务也并非完美,它本身也引入了其它复杂性,比如:
跨微服务的接口:如A服务调用B服务,效率上必定不如单体服务内部调用,前者是需要跨网络连接,而后者只是单进程下内部的方法间调用;
分布式事务:每个微服务都需要申请同名数据库,还是以A、B服务为例,如果A、B数据强关系,又分属不同数据库,势必会遇到分布式事务的问题;
单纯开发部署一个微服务的门槛其实很低,最后会演变成一个人会负责多个微服务,可能一个简单的需求需要涉及到多个微服务的迭代,如果事先没有做好规划,在部署时很容易遗漏,当然,这点可以通过一些流程去避免,不过一旦开始卡点,灵活性的优势也就不再了。
问题1其实很好解决,将A、B服务合并即可,同时也优化了前文提到 mpaas 后端服务负载过低的问题,合并后不仅可以释放闲置资源,也在无形中提高了资源利用率。当然合并是那些功能上单一、上下游依赖少的服务,笔者考虑这样的服务在合并后对业务的影响最小。在具体操作过程中,笔者接触到 monorepo 的概念,因此整个合并过程也参照了其理念,当然,这是另一个有意思的话题,暂且按下不表。
1.3 ARM 平台
这里引用我司运维同事的原话:
国外用 arm 是因为 aws,arm 机器便宜20%,腾讯云没的便宜,所以没必要
mpaas 平台的服务对架构并没有特殊的要求,在构建阶段也没有锁定平台架构,因此在得知公司在欧美区的服务部署可以支持 arm 架构之后,迅速在运维同事的帮助下,将某服务在预发环境迁移到了 arm 平台,测试一段时间后发现没有任何毛病,于是在运维的帮助下,逐一将 mpaas 平台在国外的其它服务迁移到 arm 平台架构。从结果来看,光是迁移到 arm 平台这一项举措,就直接将 mpaas 平台的成本降低了20%,可以说投入产出比非常之高了。
1.4 单实例
虽然 HA 这些词看起来貌似非常高大上的样子,但实际上,作为内部服务,mpaas 平台因为服务压力较小,真正崩溃的次数相对来说很少的,这就让高可用、多实例部署显得有些鸡肋了。某种意义上,单实例更有助于我们快速发现问题,再加上 k8s 的 deployment 的工作负载具备自动重启的能力,可以尽可能降低服务崩溃带来的负面影响。
2. 增效
2.1 内网域名
有接近一年的时间,由于对公司整个技术体系了解上的缺失,前端调用后端都是使用的办公网域名、HTTPS 协议,而事实上,前后端部署虽然分属于不同的 k8s 集群,但这两个集群都部署在腾讯云中,也就是他们其实同属腾讯云内网,内网调用自然要高效地多,我们可以预发环境的健康检查接口为例,做一个测试。
$ curl -o /dev/null -s -w 'Total: %{time_total}s\n' https://mpaas-api-gateway-cn.wgine-inc.com:7799/hc.do
Total: 0.145090s
$ curl -o /dev/null -s -w 'Total: %{time_total}s\n' http://mpaas-api-gateway-pre.in.net/hc.do
Total: 0.016823s
可以看到,同一个接口,使用内网域名的接口时延几乎是使用办公网域名的接口时间的10%,这个提升可以说是相当可观。所以我们在 mpaas 的前后端服务调用中,我们自己的服务均使用内部域名,公司内归属于其它团队外部依赖服务,敦促对方申请内部域名。经过这一番梳理和改造,mpaas 平台各项服务的用户体验又有了提升。
2.2 如何优化一个投入资源有限的项目
是的,一个投入资源有限的项目,不是因为它很成熟,只是因为不被重视,但是因为有人在使用,而不得不维护,监控平台就是这样一个例子。监控平台的数据量是 mpaas 平台最大的,单表达到了千万级别,但是这些数据大部分只是冷冰冰地被放置在数据库中,并没有被完全利用起来。笔者以为监控平台初步具备 bugly 亦或是 云捕 这样的平台服务的雏形,在投入的人员、资源如此有限的情况下,能将监控这项功能支撑起来实属不易。 如果大胆设想一下,监控平台再打磨打磨,有没有可能将其打造为 IoT 领域的 bugly,或者是成为公司增值服务的一部分?但这也许只是笔者一厢情愿的想法而已。回归正题,如果优化一个注定不被重视,不会投入过多资源,又不得不优化的平台。一开始是想着将一些历史数据删除/归档,但是删数据也是个技术活,表与表之间也存在关联关系, 光是整理这些关联关系,就让人头痛 Q2 笔者初一接手该项目的时候,从技术层面过了一次项目代码。短时间内,在业务层面很难把控全局,技术层面是一个更好的切入点,事实上那时间经常会有比较多的慢 SQL 告警,这些告警导致的结果就是监控平台的数据展示经常会非常慢,会比较影响使用者的体验。
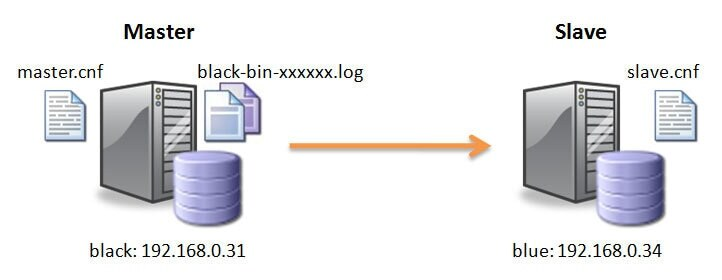
2.2.1 读写分离
监控平台在 DB 层面有一个非常显著的特点:写多读少。这在架构上比较容易想到读写分离的策略。由于沟通上的原因,初期我们并不知道欧美区的 DB 是自带从库的,这就导致监控平台无论读写全都是使用的主库,这结主库造成了沉重的负担。经过读写分离的改造,监控平台的平均性能有了显著提升。
2.2.2 SQL 优化
得益到公司 DB 平台的优化建议,笔者根据相关建议对数据库表进行查询优化(如: 加索引)等操作,结果数据库的查询性能又得到了提升。
3. 总结
降本增效,是一个需要持续的过程,并不是一蹴而就的。作为一名软件工程师,需要与时俱进,以技术为手段,不断促进业务的发展。
参考