自打我加入贵司以来,不知不觉已经一年了,这一年有太多可以回顾的事情,但其中最令我印象深刻的,当属我个人从设计、实现、兼大部分测试的非KPI驱动项目:快速部署。
先简要介绍我们组做的项目:一个大数据运维管控平台(后面以CD代称),号称对标CDH:
CDH是Apache Hadoop和相关项目的最完整,经过测试的流行发行版。 CDH提供了Hadoop的核心元素- 可扩展的存储和分布式计算 - 以及基于Web的用户界面和重要的企业功能。 CDH是Apache许可的开放源码,是唯一提供统一批处理,交互式SQL和交互式搜索以及基于角色的访问控制的Hadoop解决方案
对于不熟悉大数据的业务开发者来说,CD可以类比为为安装、部署、更新微服务的”大数据“平台版本(个人感觉这个类比要糊)
CD的过往
先说说CD的架构设计,它是一个master+agent架构,可能因为CD对外宣称支持云原生,所以Server端部署在K8s中(这因果关系是我猜的,因为已经没人知道了),agent端负责接收server端指令,完成部署和运维的工作,至于K8s,则有一套组内自研的operator与CRD,负责接收master指令,用于在K8s中部署大数据组件。master与operator、agent均通过kafka完成通信与状态同步。
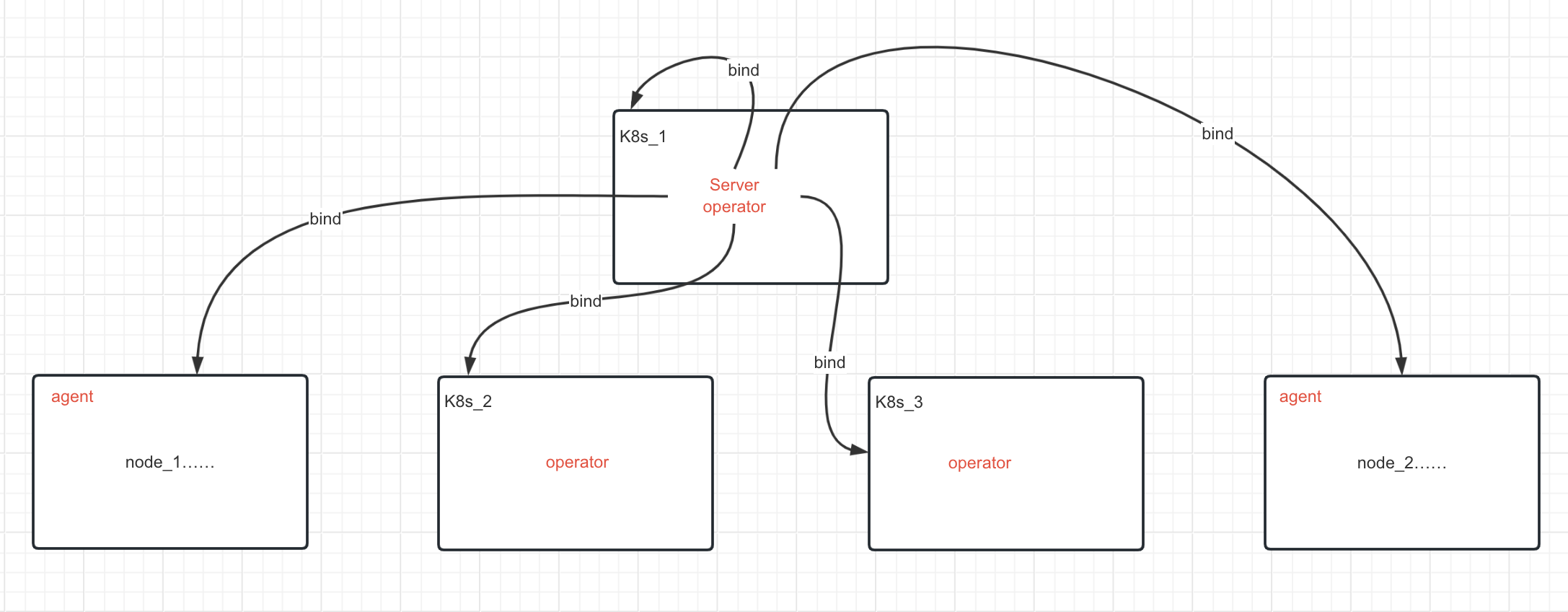
Server部署在K8s_1中,然后Server再绑定K8s_1、K8s_2、K8s_3;Server通过ansbile脚本分发agent从而绑定node_1、node_2等,作为部署大数据的资源。Server所依赖的其它中间件诸如redis、zk等就不一一列出了。
如上图所示Server部署在K8s_1上,然后Server又绑定K8s_1以作为自己部署大数据的资源,这,怎么看怎么别扭。以上大致就是CD的历史现(债)状(务)。
部署流程
从上图可看出,CD的部署至少是强依赖K8s的,这套完整的CD部署脚本是由运维写的,已经长期不维护了,这套脚本主要包括以下内容:
通过KubeSphere部署K8s(不支持arm平台,由于长期不更新,仅支持有限的K8s版本);
通过ansible脚本部署中间件依赖(包括但不限于zk、kafka、redis、es等)
在K8s_1中部署Server端
由于长期缺少维护+ansible脚本缺少lint+极度缺乏在不同环境的部署测试,这套所谓的自动化部署CD的脚本部署真实部署起来是要以“天”来计算的(不要问我为什么)。
笔者曾自发地想过要去优化这套脚本,但是只能无奈地放弃了,一无文档,二无机器资源的情况下,这套脚本想要run起来也是有些门槛的。
初衷
毕竟在前司实打实参与过降本增效的,当来到贵司时,看到这套架构,内心还是挺震惊的。redis、kafka、zk以及其它中间件都不必说了,问题是CD号称要对标的CDH也没有依赖如此多的中间件,一开始我跟老同事请教,为何要将CD的server端部署在K8s中,对方回我因为“方便”,但是从实际体验上来说,并没有,更不用提部署在K8s中的server没有做probe、prorityclass、requsts等配置了。但,但让我体验最不好的地方在于,这套CD平台没有办法本地部署,或许我可以本地部署一个minikube,因为数据持久化的要求,还得配一个NFS,再加其它中间件,我可以搞定这一套,但其它人呢?并不熟悉K8s/Ansible的首次体验这套平台的潜在用户,恐怕内心已打退堂鼓了吧……
一个不能快速试用的软件平台,是很难吸引目标用户的。虽然CD对外一直宣称要开源,然而一年过去了,没有任何实质性动作,一个老员工曾私下跟我吐槽:幸亏CD没开源,不然大概述要惨不忍睹了……
改造
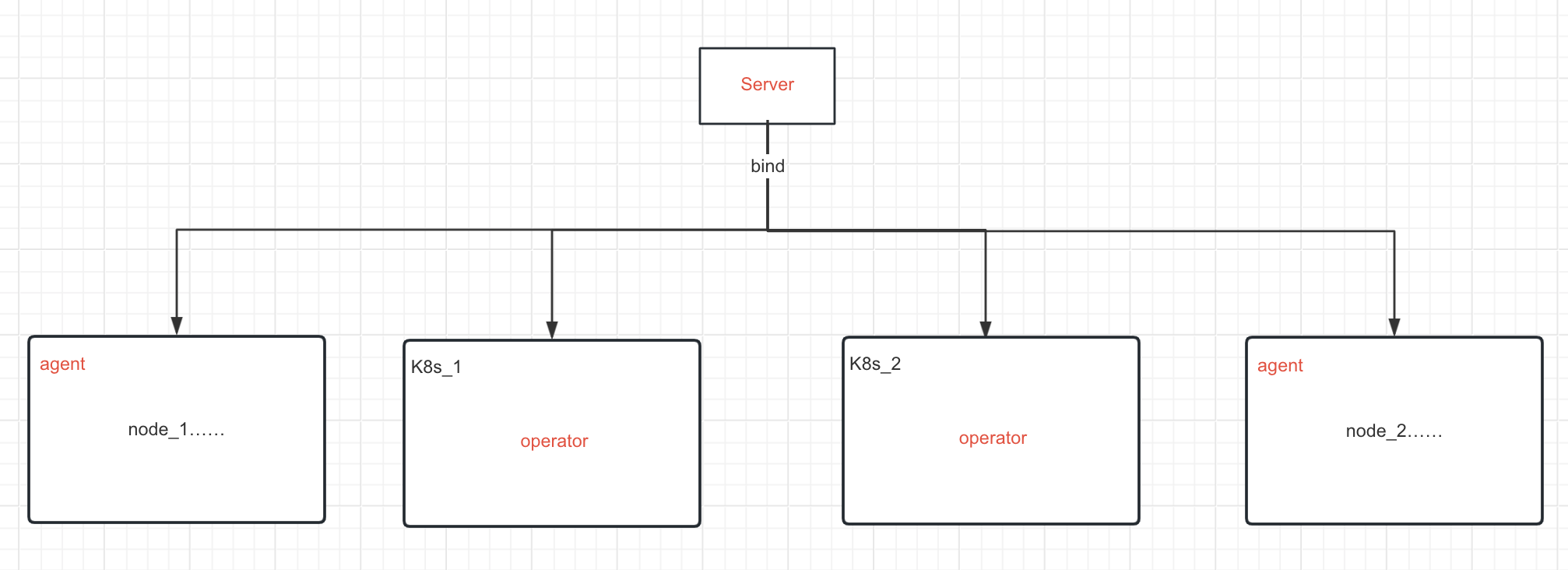
改造第一步,从设计上开始,所谓master/agent架构,逻辑上是有分层的,部署上自然也就更加清晰了。假设一个用户要使用CD这个平台,首先需要一个Server端,然后再根据客户的资源情况分发agent以及添加K8s。有了这张图做指导,一个适用于PoC阶段的快速部署模型也就呼之欲出了,没有什么比docker-compose更适合干这个事情了。
梳理依赖
服务配置项
其实有了docker-compose打底,剩下整理配置这事就是体力活了,但我是没想到整理配置也花了不少时间,比如Server端的配置,部署在K8s中时,有多个configmap,需要挂载pv,也有secret的,比较繁杂;还有CD所依赖的用户中心,是其它部门提供的,又少不了一番沟通……
中间件
CD依赖的中间件有zk、kafka、redis、es、grafana、prometheus,这些都还算简单,因为之前也是容器化部署,所以直接将旧有配置复制过来,稍作调整就可以了
雏形
.
├── README.md
├── .env
├── confd
│ ├── backend
│ ├── elasticsearch
│ ├── frontend
│ ├── grafana
│ ├── mysql
│ ├── prometheus
│ └── ucenter
├── docker-compose.yaml
将redis、mysql、es等用户名密码配置写到.env文件中;
将初始化SQL放在/docker-entrypoint-initdb.d目录下;
将各个服务的个性化配置分目录整理好,挂载到对应的容器中;
配置好healthcheck、depends_on等等
docker-compose up 就可以根据配置启动一个指定版本的CD server端了,用一个体验过的同事的话来说:太特么快了吧。
然后在一次周会上,小小show了一下我的成果,也想借此推进这个快速部署进入项目的主流程,让更多的人参与进来,从而推动快速部署与迭代同步,实现标准化。有趣的是,当我展示成果的当天,公司各个产品线就被要求提供一个能够快速部署方案,要求能在半天内完成PoC部署。可能是潜在客户对我们的以往的部署模式有诸多不满,但也可能是因为售前的同事不满,总之不可能是因为我的原因。于是,经历了这个小插曲,快速部署正式成为我的KPI了,当仁不让,就是我了。
GA
因为信创的要求,CD需要在部署在arm机器上,于是乎需要做一些改造,但配置是共用的,只是镜像不同而已。
由于启动后需要将当前机器的内网IP写入到其它服务的配置项中,于是我写了一个Makefile。
考虑到客户现场的其它状况,我又在Makefile中增加了对于docker与docker-compose版本等前置检查以及数据持久化目录和权限的初始化。
将docker-compose up与 docker-compose down等命令封装成make up与make down
一个GA版本的快速部署也就成型了。
.
├── Makefile
├── .env
├── README.md
├── confd
│ ├── backend
│ ├── elasticsearch
│ ├── frontend
│ ├── grafana
│ ├── mysql
│ ├── prometheus
│ └── ucenter
├── docker-compose.amd64
├── docker-compose.arm64
TODO
虽然已经在多个项目中推进这套快速部署,但毕竟快速部署是为PoC准备的,在单机上运行最好,如果客户强烈要求高可用部署(虽然彼时因为历史原因,CD的server端只支持单实例部署,高可用只针对kafka、zk、redis等), 在多台机器上部署,需要稍加改动,虽然改动不大,但总归还是改进的空间的,对于多机部署,我能想到以下几种方法:
docker swarm ,对的,一个现在已经没多少人提及,不少人可能觉得这是被淘汰的技术,但是,小规模容器化部署的场景,docker swarm是很适用,至少现阶段我这么认为;
使用IaC技术如pulumi、terraform来重构部署流程,没在项目中用过,很想尝试;
如果实在要部署在K8s中,我选k3s,无它,好用又轻,没理由不爱
总结
虽然我希望有他人能参与进来,但没想到,这事从头到尾包括测试都是我亲力亲为全程参与的。谁提出问题,谁就去解决问题,还要一直负责下去,讲真,蛮讨厌这样的组织文化的,至少这件事上,没看到teamwork。
快速部署这事,一开始就是出于自驱的,要在本职工作之余做这些,需要一些偏执和信念。轻量化、简洁有力一直是我做这件事的目标与驱动力,这跟KPI没有关系,我乐在其中,虽然未必能被理解。
永远将复杂留在背后,将简洁高效呈现给用户,这比繁杂的所谓安装文档有用的多。
参考: